I Replaced my App’s Core JavaScript Logic with AI — Is this the future?
Large language models (LLMs) like ChatGPT are now capable of function calling and returning JSON-formatted data. This made me wonder:
Could we completely outsource the business logic of an app to AI?
If so, what are the limits?

What This Post Covers
- Level 1: Replacing entire JavaScript functions and services by describing functionality in plain English
- Level 2: Creating React components that automatically generate interactive UIs from simple descriptions using Tailwind and Ant Design components
- Level 3: Building a fully functional Todo app where all application logic is orchestrated by GPT-4o
Let me reiterate this:
The app’s logic and functionality are outlined in plain English, with the LLM managing all decisions without traditional code. It autonomously processes user inputs, updates the UI, and interacts with databases.
😳
I’m calling this: LLM-Driven Application Orchestration
Source code:
Level 1: Replacing Functions with LLM Calls
A well-structured application consists of components, services, and modular functions. Many of these functions can be perfect candidates for delegation to LLMs.
Example 1: Detecting Anomalies in Financial Transactions
Traditional JavaScript function:
function detectAnomalies(transactions) {
let amounts = transactions.map(t => t.amount);
let mean = amounts.reduce((a, b) => a + b, 0) / amounts.length;
let variance = amounts.reduce((sum, x) => sum + Math.pow(x - mean, 2), 0) / amounts.length;
let stddev = Math.sqrt(variance);
let anomalies = transactions.filter(t => Math.abs(t.amount - mean) > 2 * stddev);
return anomalies.length ? anomalies : "No anomalies detected.";
}Example Usage:
const transactions = [
{ id: 1, amount: 100 },
{ id: 2, amount: 120 },
{ id: 3, amount: 110 },
{ id: 4, amount: 5000 }, // Outlier
{ id: 5, amount: 90 },
];Converting this to an LLM instruction:
async function detectAnomalies(transactions) {
const result = await fetchLLMAnswer(`Analyze a list of financial transactions and find any anomalies. Transactions: ${JSON.stringify(transactions)}`);
return result;
}GPT-4o still correctly identifies $5000 as an outlier. Plus, we no longer need a strict format — the LLM can detect a broader range of anomalies.
You might be thinking that result could change between calls but we can ensure a consistent output if we:
- Pass in a TypeScript return type for the LLM to adhere to
- Intruct the model to return only JSON (
response_format: { type: "json_object" }) - Reduce randomness by adjusting the temperature parameter
Example 2: Finding Duplicate or Near-Duplicate Records
Traditional JavaScript function:
function findDuplicates(records) {
let duplicates = [];
for (let i = 0; i < records.length; i++) {
for (let j = i + 1; j < records.length; j++) {
let nameMatch = records[i].name.toLowerCase() === records[j].name.toLowerCase();
let emailMatch = records[i].email.toLowerCase() === records[j].email.toLowerCase();
let addressSimilarity = records[i].address.split(" ").filter(word => records[j].address.includes(word)).length > 3;
if (nameMatch || emailMatch || addressSimilarity) {
duplicates.push([records[i], records[j]]);
}
}
}
return duplicates.length ? duplicates : "No duplicates found.";
}Example usage:
const records = [
{ name: "John Doe", email: "john@example.com", address: "123 Baker Street, London" },
// Near duplicate:
{ name: "john doe", email: "john.d@example.com", address: "123 Baker St., London" },
{ name: "Jane Smith", email: "jane@example.com", address: "456 Elm Street, Manchester" }
];Converting this to an LLM instruction:
async function findDuplicates(records) {
const result = await fetchLLMAnswer(`Find duplicate or near-duplicate entries in this dataset: ${JSON.stringify(records)}.`);
return result;
}The LLM approach scales effortlessly and adapts to new record types without updating the function manually.
Level 2: Generating UI Components from Plain English
Imagine a React component that generates a fully functional UI from a plain English description:
<LLMRenderer
instructions="Build a UI displaying the user's name and phone number, adding a funny remark about them. Include a button that opens a modal where the user can input their phone number."
data={{ userName: "Tom Jones" }}
stateControllers={{ showModal, setShowModal, phoneNumber, setPhoneNumber }}
/>And in seconds, a fully interactive UI is rendered, incorporating the data, state, and callbacks you provided to use:
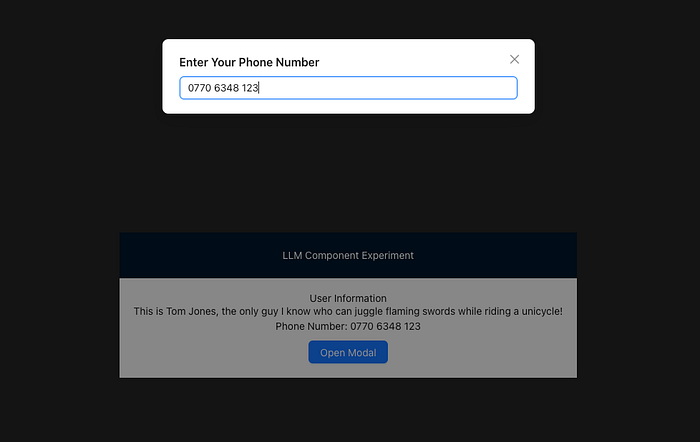
This is exactly what I built, and it works better than expected!
Find the source code here:
https://github.com/webondevices/llm-wizard/blob/main/src/LLMRenderer/LLMRenderer.jsx
The LLMRenderer component:
- Takes plain English instructions, data, and state controllers as input
- Sends these instructions to an LLM (ChatGPT/GPT-4/Claude)
- The LLM returns a JSON-based UI tree structure
- The UI definition is then rendered dynamically and recursively
Example JSON output that the LLM gives us:
{
"ui": {
"type": "div",
"props": {},
"children": [
{
"type": "Input",
"props": {
"placeholder": "Enter a task",
"value": "{{taskName}}",
"onChange": "{{() => handleTaskNameChange('new name')}}"
}
},
{
"type": "Button",
"props": {
"type": "primary",
"onClick": "{{() => addTask()}}"
},
"children": "Add Task"
}
]
}
}The recursive rendering system then:
- Maps each JSON node to Ant Design components
- Attaches event handlers and state (
{{ }}syntax)
Just for fun, I also built a Tailwind version:
<LLMTailwind
instructions="Build a UI displaying the user's details in a card with a button to toggle between large and small views."
data={userData}
stateControllers={{ toggle, setToggle }}
/>https://github.com/webondevices/llm-wizard/blob/main/src/LLMTailwind/LLMTailwind.jsx
Level 3: Replacing Application Logic Entirely
We know LLMs are slow and expensive today, but they are improving at an incredible pace. We already have models with over 900 tokens per second speed, and response times will likely drop below 100ms in a year or two. Even today, with GPT-4o-mini, the whole process takes less than a second in my tests.
So, how does it all work?
The Future: AI-Orchestrated Apps
Instead of writing traditional code to handle the UI and communicate with the APIs, we define:
- App goals (e.g., “Allow users to manage tasks”)
- Features (e.g., “Add, delete, prioritise tasks”)
- Available UI Components (e.g.,
Ant Design,Material UI, or custom components) - Available API Endpoints for data access
To demonstrate the behaviour, I built a simple todo app:
https://github.com/webondevices/llm-wizard/blob/main/src/Todo/Todo.tsx
Lets see how it works step-by-step:
1. Creating the UI
The LLM generates a UI dynamically using <LLMRenderer /> or <LLMTailwind /> but we also have the option to just provide a static JSX.
Next, we import the useLLMOrchestrator that handles communication with the chosen LLM (GPT-4o-mini in my case).
const { handleInput } = useLLMOrchestrator({
states: { modalOpen, todos, newTodo },
actions: {
openModal: {
fn: () => setModalOpen(true),
description: "Opens the modal dialog for adding a new todo item"
},
// ...
addTodo: {
fn: (todoName: string) => setTodos(prev => [...prev, {
id: crypto.randomUUID(),
name: todoName,
completed: false
}]),
description: "Adds a new todo item to the list with the specified name"
},
// ...
} as TodoActions,
});2. Defining context and available actions
We pass the available state variables of the app into the hook, allowing the LLM to understand exactly what’s happening. We also provide a list of actions it can use.
3. Let the LLM know what happened
Finally, the hook exposes a handleInput function. Anytime an event happens in the app or the user interacts with the UI — such as clicks a button — we simply call this function with a plain English explanation of what happened:
// Create a new task
handleInput(`user wants to create a new task called ${newTodo}`)
// Open modal
handleInput(`user clicked the open new task modal button`)
// Close modal
handleInput(`user clicked the close modal button`)
// Completing a task
handleInput(`user clicked to toggle todo with id ${todo.id}`);The AI assistant then processes the request and determines the best course of action or sequence of actions to perform. It then executes those actions accordingly.
When we start the app, we have an empty list of tasks:
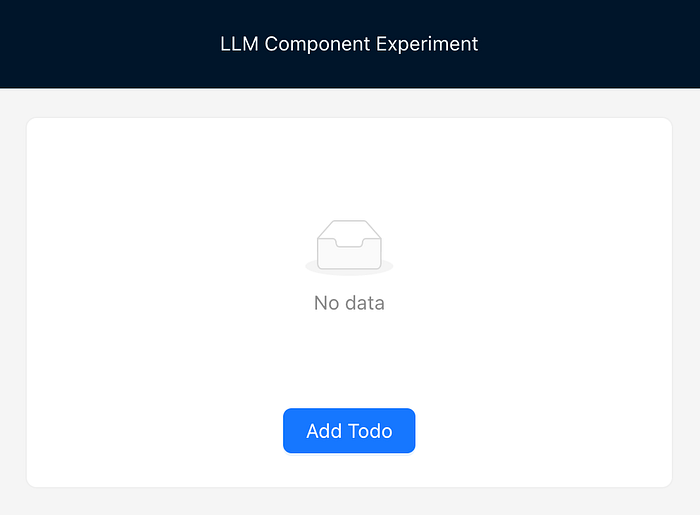
If I click the “Add Todo” button, I notify GPT-4o-mini that a certain button was clicked. The model then decides that the best course of action is to open the modal and clear the input field:
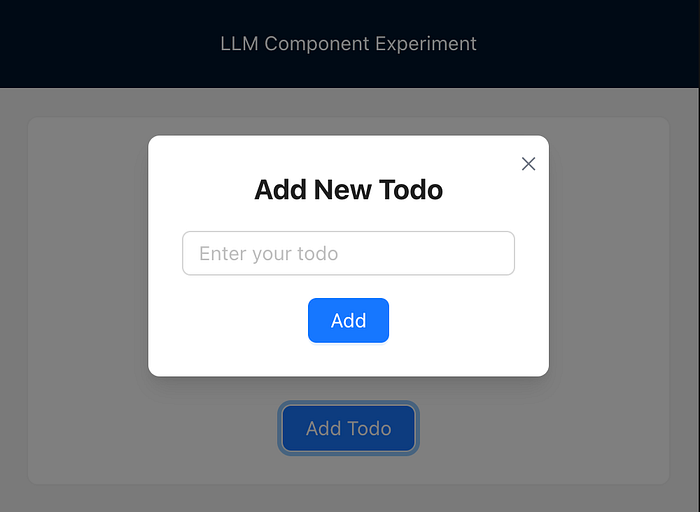
Once a new todo name is entered and the Add button is clicked, again, we don’t manually handle any logic. Instead, we just inform the LLM of what happened in the UI, and it performs the necessary actions:
- Save the new todo
- Clear the input field
- Close modal
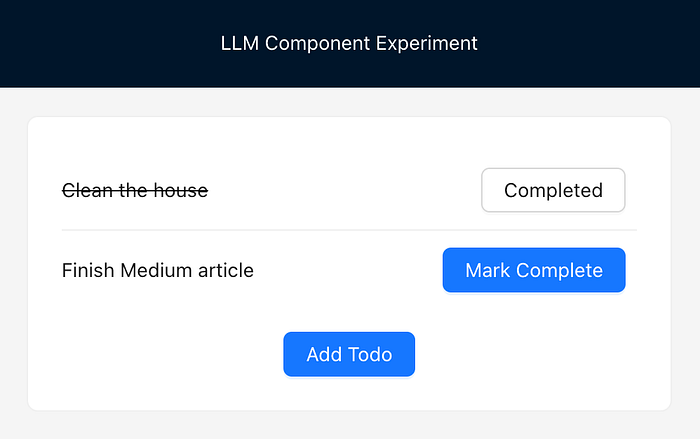
And with that, the app works end-to-end — without any traditional JavaScript application logic!
Closing thoughts
LLM-Driven App Orchestration is both exciting and a little scary at the same time. What started as a quick experiment ended up working surprisingly well. I can absolutely see how a system like this could fully manage an app by simply describing the available UI elements, their settings, available actions, API endpoints, and an overall app goal with a list of supported features.
Is this how apps of the future will work?
Let me know what you think!